In a Compute Engine environment, managed instance groups (MIGs) offer autoscaling that lets you automatically change an instance group’s capacity based on current load, so you can rightsize your environment—and your costs. Autoscaling adds more virtual machines (VMs) to a MIG when there is more load (scaling out), and deletes VMs when the need for VMs is lesser (scaling in).
When load declines, the autoscaler removes all unused capacity. This allows you to save costs but might cause the autoscaler to scale in abruptly. For example, if the load goes down by 50%, the autoscaler removes ~50% of your VMs immediately after a 10-minute stabilization period. Deleting VMs so abruptly might not work well for some workloads. For example, if your VMs take many minutes to initialize you might want to slow down the rate at which you scale in to maintain capacity for imminent load spikes.
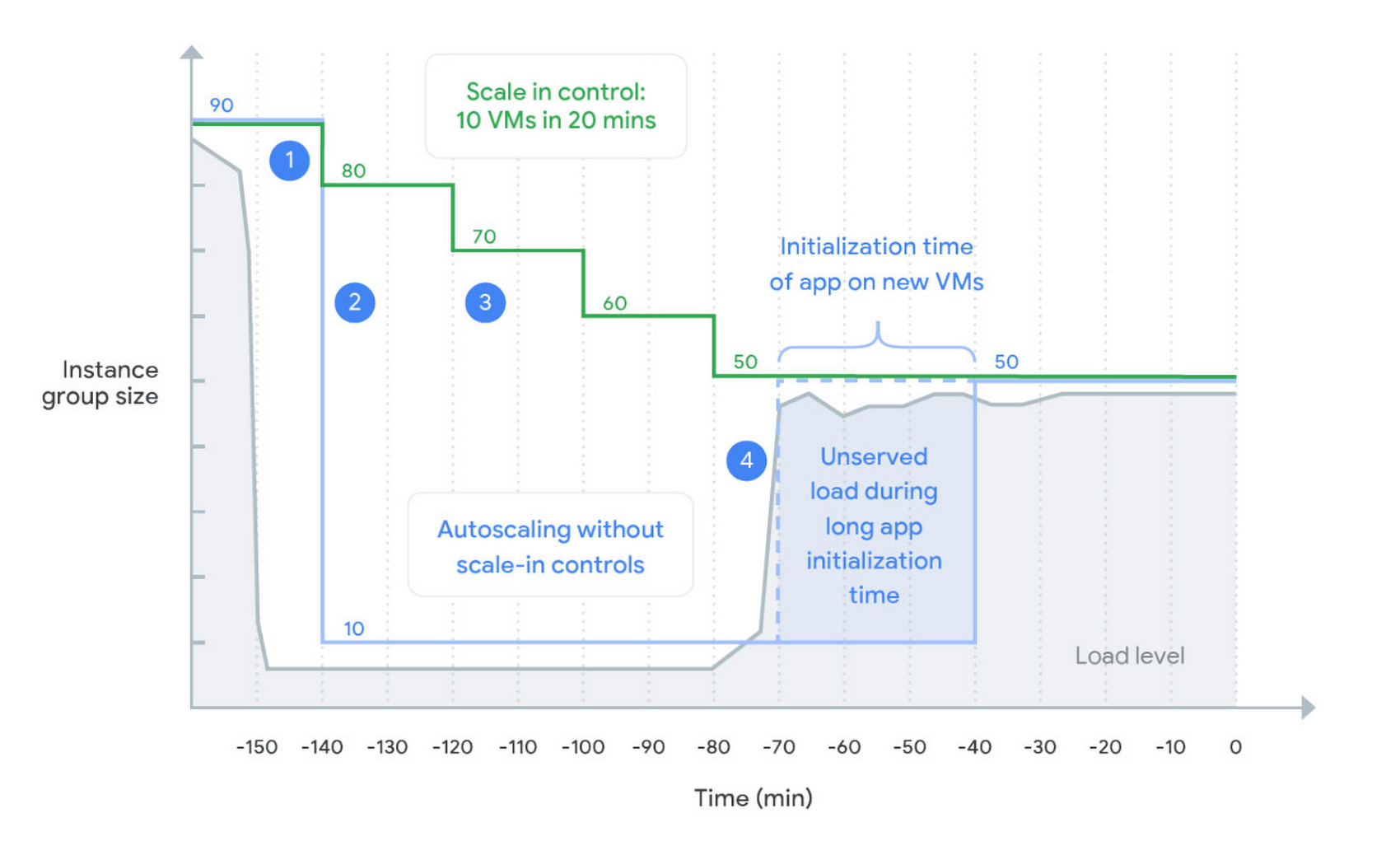
1. When load declines, the autoscaler maintains the size for the group at a level required to serve the peak load observed in the last 10 minutes (the stabilization period). This works the same with and without scale-in controls.
2. An autoscaler without scale-in controls keeps only enough instances required to handle the recently observed load. After the stabilization period, the autoscaler removes all unneeded instances in one step. A sudden drop in load can lead to a dramatic reduction of instance group size.
3. An autoscaler with scale-in controls limits how many VM instances can be removed in a given period of time (here 10 VMs in 20 minutes). This slows down the instance reduction rate.
4. With the load spikes again, the autoscaler adds new instances. However, because VMs take a long time to initialize, the new VMs aren’t ready to serve the load. With scale-in controls, the previous capacity wasn’t deleted yet, allowing existing VMs to serve the spike.